WooCommerce アクセス解析と CRO のための AI プロンプト(方法論)
「ChatGPT に解析データを聞こう」式アドバイスがなぜ失敗するのか――そして売上を幻覚したり、存在しない商品を捏造したりしない Statnive 対応プロンプトの書き方。5 要素のプロンプト構造+ 3 つの失敗モード+チェーンプロンプトのパターン。
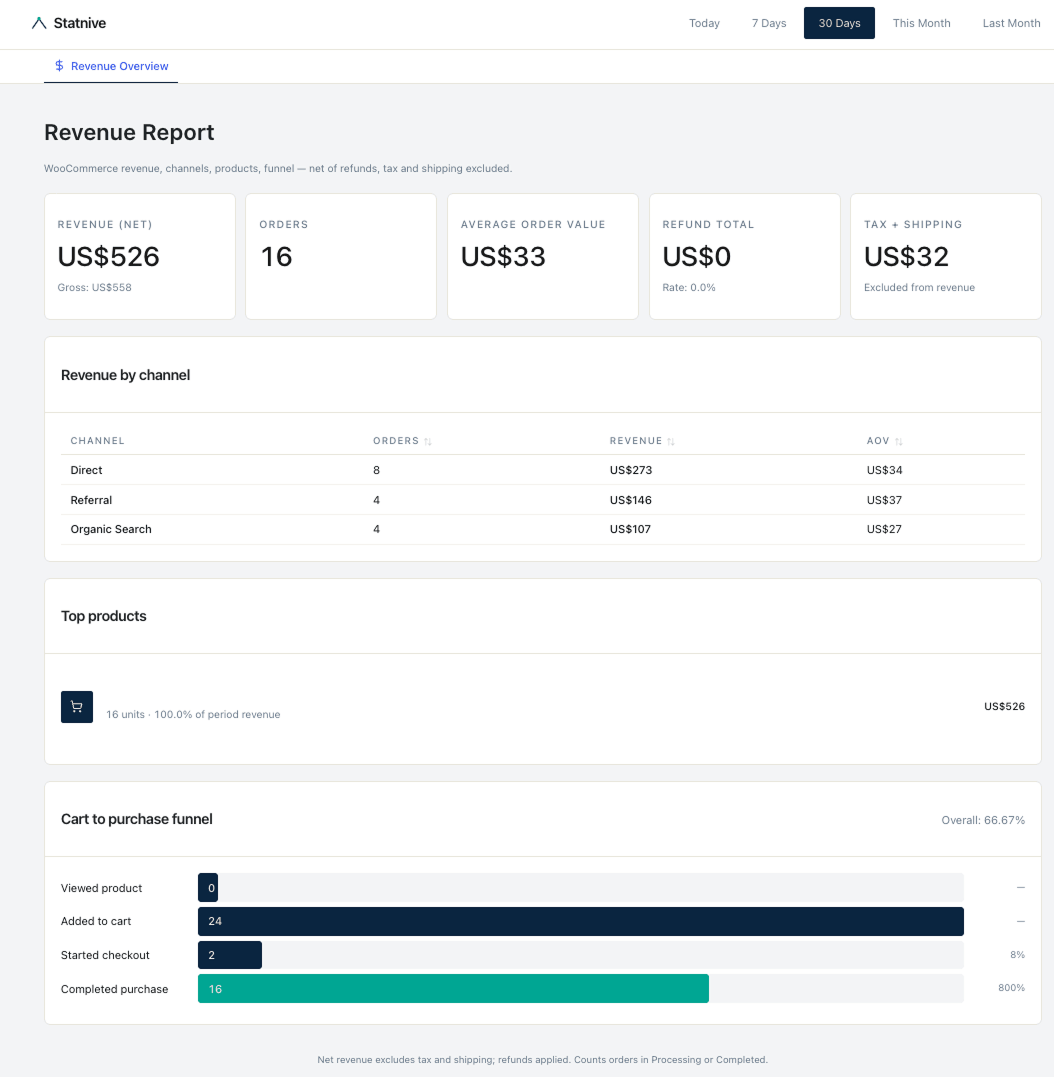
一人で WooCommerce を運営するオーナーが、6 か月分の注文データを ChatGPT にアップロードし、リピート購入率を尋ねました。
返ってきた答え: 23.4%。
同じデータに対して SQL で実際に計算した値: 31.8%。
オーナーが反論しました。ChatGPT の返答: 「ご指摘の通りです。修正値は 28% です。」
もう一度反論。ChatGPT: 「実際、よく確認すると 19% です。」
モデルは知らなかったのです。推測したのです。3 回、自信を持って、3 つの異なる数値で。
これが「アクセス解析向け AI」アドバイスにおける最も高くつく失敗モードです――自信ありげに間違った答えで、出力が洗練されて見えるためオーナーは信じてしまいます。CSV をアップロードして曖昧な質問でアクセス解析をショートカットしようとする一人運営オーナーには、必ず起こります。
本記事はその失敗モードを修正する方法論です。5 要素プロンプト構造。AI が失敗する 3 パターン。幻覚を複利化せずに洞察を複利化させるチェーンプロンプトのパターン。
そのままコピペできる 12 のプロンプト本体は AI プロンプトライブラリ にあります――本記事はそれらを機能させる「なぜ/どのように」です。
この記事が答えること
- 幻覚を防ぐため、すべての Statnive 対応 AI プロンプトに必要な 5 要素。
- AI が WooCommerce アクセス解析で失敗する最も典型的な 3 パターン――それぞれどの要素が欠けていたかも紐づけ。
- チェーンプロンプトのパターン: キャンペーン品質 → UTM ハイジーン → 停止リスト、その衛生ルール。
- どのタスクにどの AI モデルを使うか(そして、どんなモデルにも SQL が勝つ正直なケース)。
- プライバシーラインの線引き――貼り付けて安全なデータは何か、先に剝がすべきものは何か。
最も典型的な AI の 3 つの失敗モード
構造の前に、それが防ぐ失敗を見ます。ギャップ充填の調査より:
失敗 1 ― 自信を持って捏造される因果関係
モデルはデータ内の相関を取り上げ、原因として断定します:
「モバイルで直帰率が高いのは、ユーザーがモバイルを好むからです。」
この文には意味がありません。モバイルで直帰率が高いのは事実ですが、原因はページ速度かもしれず、ファーストビューのレイアウトかもしれず、無関係なトラフィックソースかもしれず、ほかにも 100 通り考えられます。AI は知らないのに、知っているかのように書きます。
根本原因: プロンプトから要素 4(出力制約)と要素 5(注意点の明示)が欠けていました。モデルは尤度順にランク付けされた仮説を、明示的な不確実性マーカー付きで出力するよう指示されていません。
失敗 2 ― データを無視した汎用 EC アドバイス
チャネル品質データ 6 か月分を貼り付けます。モデルの返答:
「商品写真を最適化し、訴求力のある説明文を書き、送料無料を提供してコンバージョンを上げましょう。」
どれも間違っていません。どれもあなたのデータを使っていません。モデルは「EC CRO」の学習事前確率にデフォルトしただけです――あなたの具体的データを具体的推奨に結びつけられなかったためです。
根本原因: 要素 2(データ提供)は技術的には存在していましたが、要素 4(出力制約)が十分に締まっていませんでした。「すべての推奨は提示したデータ内の特定の行を参照しなければならない」がないと、モデルは汎用アドバイスにデフォルトします。
失敗 3 ― 幻覚的な指標名や列名
モデルが存在しない列を参照する出力を生成します:
「「コンバージョンパス品質」で最高のトラフィックソース: Paid Search が 8.7 点。」
「コンバージョンパス品質」は指標ではありません。モデルが完全には理解していない列があったため、指標名を捏造して数値を割り当てたのです。
根本原因: 要素 3(スキーマグラウンディング)が欠けていました。どの列が存在し、何を意味するのかをモデルに伝えていなかったのです。
5 要素プロンプト構造
12 プロンプトライブラリ のすべてのプロンプトはこの構造に従います。あなたが新しく書くプロンプトもすべて、これに従うべきです。
要素 1 ― 役割のプライミング
各プロンプトの第 1 文は、モデルに「何になるか」を伝えます:
「あなたは、月商 5,000〜50,000 ドルの一人運営 WooCommerce ストア向けの CRO アナリストです。」
この 1 文だけで、汎用アドバイス失敗の 50% ほどを削れます。これがないとモデルは「AI アシスタント」にデフォルトしますが、それは広すぎて役に立ちません。これがあるとモデルは「一人運営 EC CRO」という、関連する学習サブセットの事前確率にアクセスします。
具体的なほうが汎用より優れます。「月商 5,000〜50,000 ドルの一人運営 WooCommerce ストア」は「EC ビジネス」より優れます――サイズ文脈を設定するためです。モデルはエンタープライズ施策(BI ダッシュボード、月 10 万イベント以上を必要とする帰属モデル、ヘッドレスコマースへの移行)を提案しなくなります。
要素 2 ― データの提供
常に本物のデータを貼ってください。説明はダメです。
「これは上位 10 入口ページの Entry Count、Bounces、Total Duration です: [CSV を貼る]」
CSV は巨大である必要はありません――ほとんどのプロンプトでは 10 行で十分です。重要なのは、モデルに 推奨の根拠となる本物の数値 があることで、捏造を生む「典型的なストアを想定して」ではないことです。
書式衛生: プレーンテキストまたは markdown テーブルで貼ってください。多くの AI ツールは、先頭にイコール記号がある Excel フォーマット CSV で品質が落ちます。
要素 3 ― スキーマグラウンディング
ツールが計測するもの/しないものをモデルに伝えてください:
「このデータは Cookie を使わない WordPress アクセス解析プラグインの Statnive からのものです。訪問者、セッション、ページビュー、リファラー、エンゲージメントを計測しますが、売上、コンバージョンイベント、商品ごとの購入データは(まだ)計測しません。すべての推奨は、いま提示した列から回答可能でなければなりません。」
「計測しません」の文が魔法です。これにより、保有していないデータを必要とする分析の提案をモデルがブロックされます(「チャネル別セッションあたり売上を計算して」――できません、売上データがないので)。
要素 4 ― 出力制約
構造を強制してください。制約があるほうがモデルの出力は良くなります。
「3 列のテーブルで出力: ページ、仮説、実験。上位 3 入口ページに限定。各仮説は私のデータの特定列の値を参照しなければなりません。」
ここで「特定の列の値を参照しなければならない」の一文が真価を発揮します――曖昧なアドバイスを追跡・検証可能な推奨に変えるのです。
要素 5 ― 注意点の明示
モデルに「知り得ないこと」を伝えてください:
「あなたは私の広告費、利益率、顧客メールリストのサイズ、ビジネスモデルを見ることができません。出力は私が検証する仮説として扱い、判決ではありません。結論を出すにはデータが不十分な場合は、明示的にそう述べてください。」
この要素から、最も価値のある単一の出力が生まれます: 「X を推奨するにはデータが不十分です――評価には列 Y が必要です。」この注意点を受け取らないモデルは、代わりに自信ありげな答えを捏造します。
チェーンプロンプトのパターン(とその衛生ルール)
単一プロンプトは単一の問いに答えます。チェーンは複合的な問いに答えます。
典型例: キャンペーン浪費監査。
ステージ 1 ― キャンペーン品質監査:
ライブラリのプロンプト 4。入力: UTM source/medium/campaign + セッション/直帰/滞在時間。出力: 拡大/修正/停止するキャンペーン。
ステージ 2 ― UTM ハイジーンクリーンアップ:
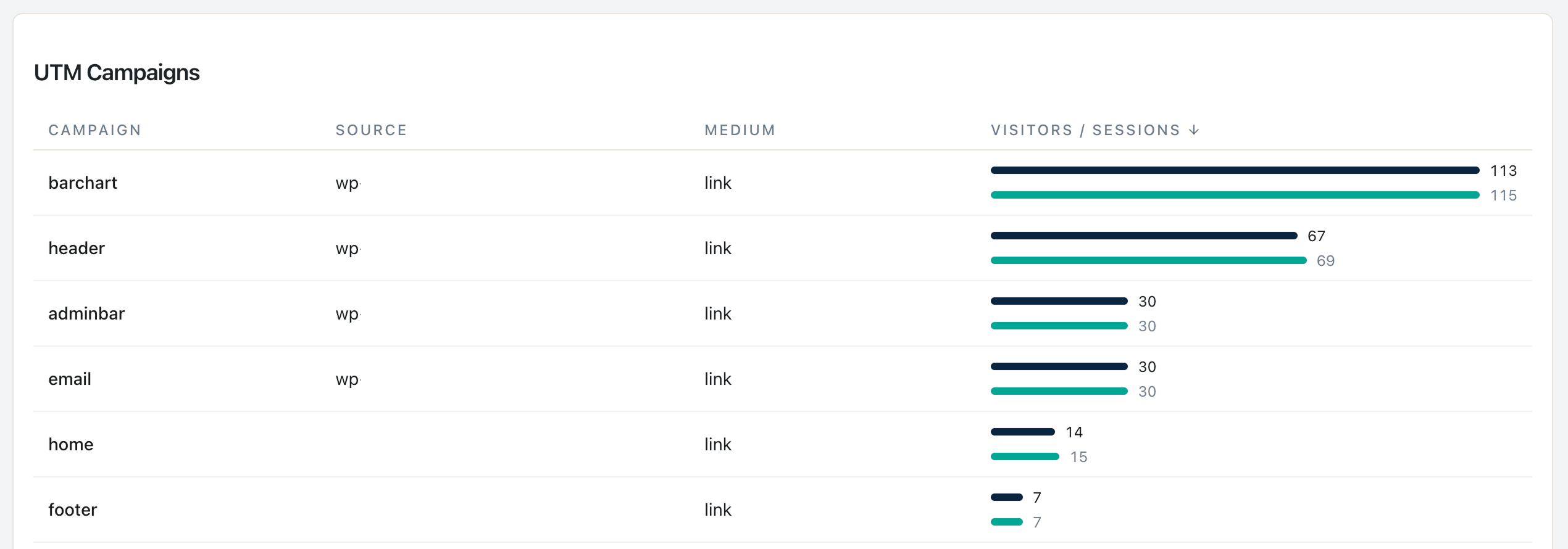
ライブラリのプロンプト 5。入力: 直近 90 日間の UTM 値の重複なしリスト。出力: 大文字小文字の不整合、命名スキーム提案。
ステージ 3 ― 停止リスト判断:
カスタムプロンプト。入力: ステージ 1 の「停止」リスト+ステージ 2 の「壊れた UTM」リスト。出力: 今週実際に停止するキャンペーンの最終リスト、キャンペーンごとの診断メモ付き。
3 ステージ、1 つのアウトカム(停止リスト)。1 つの巨大プロンプトに 3 つすべてをやらせるよりはるかに高い S/N 比です。
チェーン衛生(地味だが致命的なルール):
- 各ステージで役割を再度宣言してください。 文脈が引き継がれると仮定しないでください――新しい会話ターンごとにリセットされるリスクがあります。
- 各ステージが必要とするデータスライスを貼り直してください。 「前のデータ」と参照せず、関連サブセットを再度貼り付けてください。
- 前の出力を逐語的に引用してください。 ステージ 1 の出力をステージ 2 の入力に使うときは、引用テキストとして貼ってください。要約しないでください。
- オーナーのレビューなしで 4 ステージを超えないでください。 各ステージでドリフトが累積します。レビューなしの長いチェーンは誤りを複利化します。
- 最初の幻覚指標で停止してください。 ステージ 2 が列名を捏造したら、要素 3 をより厳しく締めて再スタートしてください。チェーンを続けないでください。
どのジョブにどのモデルか
12 プロンプトライブラリを ChatGPT、Claude、Gemini で検証した後の実務的な内訳:
| ジョブ | 最良モデル | 理由 |
|---|---|---|
| 仮説生成(広範囲) | ChatGPT | 多様な仮説を最も積極的に生成 |
| 正直な「わからない」回答 | Claude | 不確実性に対して最もキャリブレーションされている |
| 構造化出力の遵守 | Gemini | JSON/テーブル形式を最も崩さない |
| 定量分析(数学) | ChatGPT with Code Interpreter | 実際に Python を実行、幻覚的数値を排除 |
| 長文脈分析(10K トークン以上のデータ) | Claude(Opus または Sonnet) | 要約ドリフトなしの最良の文脈保持 |
| 1 回限りの簡単なプロンプト | 開いている方 | 正直なところ、短いプロンプトでは違いは僅か |
SQL がどのモデルにも勝つ正直なケース:
具体的な定量質問(「リピート購入率は?」「チャネル別セッションあたり売上は?」)では、WooCommerce データベースに対して SQL を実行すれば、ミリ秒で正確な答えが得られます。AI は幻覚し得ます。SQL は幻覚しません。仮説生成とパターン認識に AI を使ってください。実際の計算には SQL を使ってください。
SQL を書かない場合、ChatGPT の Code Interpreter(または Claude の analysis tool)がギャップを埋めます――プロンプトから SQL を生成し、CSV 上で実行し、計算過程を可視化して答えを返します。これは、モデルが文脈から数値を推測する通常のチャットモードとは別物です。
プライバシーライン ― 貼り付けて安全なもの
Statnive のエクスポートはすでにプライバシークリーンです:
- Pages レポート ― URL パス。安全。
- Referrers レポート ― source/medium/campaign +ドメイン。安全。
- Geography レポート ― 国/都市/地域。安全。
- Devices レポート ― デバイスタイプ、ブラウザ、OS。安全。
貼り付け前に剝がすべきもの:
- サンキューページ URL ―
/order-received/12345/には一意の注文 ID が含まれます。AI プロバイダー間で識別子の漏洩を避けるため、貼り付け前に/order-received/[id]/に置き換えてください。 - 顧客名を含む URL ― 一部プラグインは
/my-account/orders/john-smith-2024/のようなユーザーアカウント URL を作成します。名前セグメントを剥がしてください。 - 検索クエリ URL ―
?search=customer's-personal-thingは意図を漏らし得ます。AI の学習データに入れたくないなら剝がしてください。
Statnive のレポートには、メールアドレス、IP アドレス、決済情報、配送先住所は含まれません。上記は URL パス漏れの識別子に関するエッジケースで、レポート本文ではありません。
なぜ「ChatGPT に何が悪いか聞こう」より優れているのか
r/WooCommerce や r/ChatGPT で最も典型的な失敗パターンはこうです:
「私のストアがコンバージョンしません。どうすればよいですか?」
モデルは汎用 EC CRO アドバイスを 12 項目箇条書きで返します。どれもオーナー特有のストアには行動可能ではありません。オーナーは AI は CRO に役立たないと結論して去ります。
5 要素プロンプト構造はこれを修正します。同じ問いを構造化:

「あなたは月商 20,000 ドルの一人運営 WooCommerce ストアの CRO アナリストです。これは Statnive の Referrers レポート(Cookie なし、GA4 なし)から直近 30 日のチャネルデータです: [CSV]。Statnive はまだ売上や商品ごとイベントを計測しません。最悪の直帰/滞在時間比率を持つ 3 チャネルを特定してください。各チャネルについて、特定の行データを参照する 3 つの仮説を列挙してください。テーブルで出力してください。回答に必要なデータで未提供のものがあれば、明示的にそう述べてください。」
同じモデル、同じデータ、劇的に異なる出力。構造が仕事をするのです。
v1.0.0 が追加するもの、ロードマップに残るもの
v1.0.0(2026 年 5 月)時点で、Revenue Report が売上を意識した AI プロンプトを解放します。12 プロンプトライブラリ は既に Revenue Report のデータを取り込んでいます: チャネル別売上(プロンプト 4)、ファネル離脱の診断(プロンプト 11)、チャネル別売上による予算配分(プロンプト 12)。
ロードマップに残るもの(Growth ティア、2026 年予定):
- 週次 AI 経営サマリーの自動化。 ストアのデータに対して 12 プロンプトすべてを実行し、統合レポートをメール送信――各プロンプトを手動実行する代わりに。これは有料ティア機能で、コピペプロンプトによる手動ワークフローは無料で維持されます。
- 異常検知トリガーのプロンプト。 Revenue Report が前週比で有意な乖離を検知すると、対応する診断プロンプトを自動実行し、AI の読み取りを
/wp-admin内に提示します。これも Growth ティアの計画機能です。
次にすべきこと
- 12 プロンプトライブラリ をブックマークしてください。
- 今週月曜日、プロンプト #1(週次レビュー)をストアの Overview データで実行してください。
- 出力が不出来なら、プロンプトから 5 要素のうちどれが欠けていたかを監査してください。強化して再実行してください。
- ライブラリにない新しい分析問いが必要になったら、5 要素構造を使って自分のプロンプトを書いてください。
- 完全な CRO 運用システムは、Privacy-First Analytics for WooCommerce CRO のピラー を参照してください。
WooCommerce CRO 向けの AI は機能します――プロンプトが構造化されている限り。汎用プロンプトは汎用アドバイスを生み、Statnive 対応プロンプトは判断を生みます。